
We interviewed Beam’s co-founder and Head of Data Science, Nicolas Gonatas, to unpack his philosophy around building the Beam risk engine.
Nic, tell us about your background.
After graduating from the University of the Witwatersrand with a BSc in Actuarial Science in 2019, I joined PwC as an Actuarial Analyst working across several sectors including Life, Health and Short-term Insurance, Banking and Financial Instrument Valuation. I later moved into the Data Science team since I had a coding background and was somewhat proficient in Python. This move started when I was posted to a team that was tasked with translating actuarial models into Python code in order to better scale up and handle vast amounts of data. We then started to just build our own models from the ground up, and that’s pretty much data science. I worked on that for around two years, ending up managing the team. We consulted to the large Telcos and Banks, building machine learning and risk models – essentially data science within the Actuarial space. Shortly after, I co-founded PYGIO, a software engineering company with Dimitri and Ronnie, where we joined forces with Tim and Adam on Beam.
What is your role at Beam?
I’m a co-founder of Beam and my role is Head of Data Science, so I look at data, seeing what we require and using novel techniques and modelling practices to predict and manage risk better.
What is your approach or philosophy around data science and risk modelling?
Our core thesis at Beam is that the world has fundamentally changed and that there’s an opportunity to move away from traditional credit scoring methods that use parametric approaches. In this approach, you make assumptions that data follows a particular distribution, together with a series of simplifying assumptions to make a limited class of statistical models make predictions. This approach contrasts with non-parametric methods, which do not assume a specific form for the underlying distribution and are more flexible in adapting to the data’s shape – we subscribe to the latter methodology at Beam.
There are three secular trends driving what’s happened in the last 20 years of machine learning advances. Number one is data. As I’ve said before, there’s more data being generated today than ever before. Think of the footprint one leaves with their bank transaction (think credit card) data, whereas previously it was all cash and was thus untracked. Not to mention the data being generated by one’s internet and social media footprint!
The second piece is compute power. If you look at Moore’s Law, it refers to how exponential growth is at the heart of the rapid increase of computing capabilities. The law was first described by Gordon E. Moore, the co-founder of Intel, in 1965 and it was the observation that the number of transistors on computer chips doubles approximately every two years.
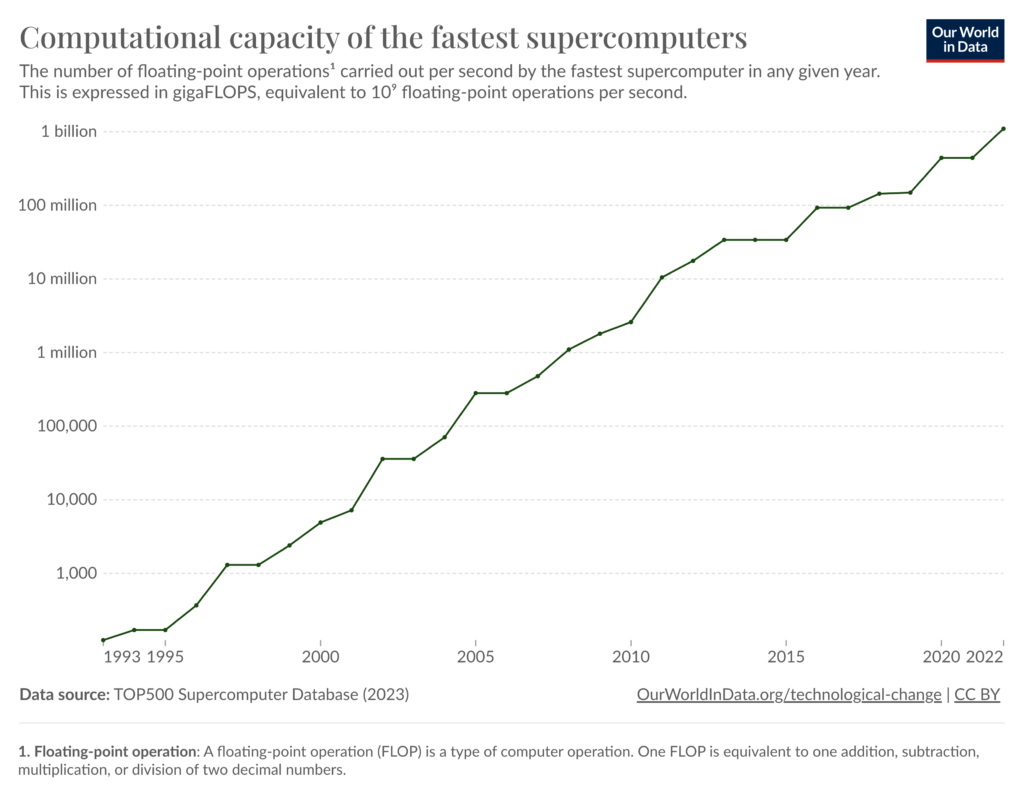
In the last 20 years, the combined processing power that is used to train these machine learning models has doubled every 12-24 months, which seems crazy and it looks like the curve is a hockey-stick.
Then the third piece is the modelling architectures that have come out over the past 2 decades, specifically concerning deep learning. For example, at university we were taught to solve statistical problems by hand – using pen and paper. This is one of the reasons for the simplifying assumptions I mentioned above: neat mathematical equations make for easier calculations! Now, when your data comes in unstructured formats, in many thousands of dimensions, these pen-and-paper techniques fail. Fortunately, modern machine learning allows us to better understand and model this data, unlocking new potential use cases previously out of reach.
In summary, at Beam, our thesis as a business is to use these three secular trends to disrupt the credit industry. We look at how credit scoring is done by the incumbents, what’s regulated and then what’s possible. We’re about using big data, modern data science principles and novel modelling techniques to unlock value for our customers – and we see that as a long-term competitive edge. We hope that by doing this we can generate much better outcomes by being able to credit score someone just with their bank statements.
So I think philosophically that sums up Beam’s data science practice. I think we’re still in the very early stages of a new era of data science and industries like credit and lending are poised for disruption given these trends.
About Beam
Beam is a fintech company founded in South Africa. Our software solution helps organisations make better credit decisions by seamlessly distilling a broad range of data sources in real-time
We enable risk officers to access all the information they need to analyse their customers in one place, and make it easy to make more informed choices throughout the credit and risk lifecycle. Our state-of-the-art software and API-driven model enable better collaboration and visibility between credit professionals, technical teams and management.



